HPC Cluster - High Performance Computing Cluster für hohe Ansprüche
HPC Cluster findet man in technisch-wissenschaftlichen Bereichen, so z.B. bei Universitäten, Forschungseinrichtungen und Forschungsabteilungen von Firmen. Die dort zu erledigenden Aufgaben, wie zum Beispiel Wetter- oder Finanzprognosen, werden häufig im HPC Cluster in kleinere Teilaufgaben zerlegt und dann auf die Cluster Nodes verteilt.
Wichtig hierbei ist dann die Cluster interne Netzwerkverbindung, da die Cluster Nodes sehr viele kleine Informationen austauschen. Diese müssen auf schnellstem Weg von einem Cluster Node zu einem anderen Cluster Node transportiert werden. Deshalb muss auf eine kurze Latenzzeit des Netzwerkes geachtet werden. Weiterhin ist wichtig, dass die benötigten und erzeugten Daten von allen Cluster Nodes eines HPC Clusters zur gleichen Zeit gelesen oder geschrieben werden können.

Hier finden Sie unsere HPC Cluster



besonderes Highlight
24x 3.5" Laufwerkeinschübe
- 2HE Rackmount Server, bis zu 205W cTDP
- Dual Sockel P+, 3rd Gen Intel Xeon Scalable Prozessoren
- 16x DIMM-Steckplätze, bis zu 4TB RAM DDR4-3200MHz
- 24x 3.5 SATA3/SAS3 hot-swap Laufwerkeinschübe
- 3x PCI-E 4.0 x16 Expansion-Slots (2x LP & 1x AIOM)
- 5x heavy-duty 8cm Lüfter
- 2x 1600W redundante Netzteile (Titanium Level)

besonderes Highlight
Bis zu 3 GPUs pro Node
- 2HE Rackmount Server, bis zu 270W TDP
- Single Sockel P+, 3rd Gen Intel Xeon Scalable Prozessoren
- 8x DIMM-Steckplätze, bis zu 2TB RAM DDR4-3200MHz
- 2x 2.5 Zoll Hot-Swap NVMe-Laufwerkeinschübe
- 3x PCI-E 4.0 x16 FHFL DW Steckplätze
- 2x M.2-Steckplätze und AST2500 BMC
- 2600W redundante Netzteile (Titanium Level)

besonderes Highlight
Integrierter SAS HBA
- 2HE Rackmount Server, bis zu 205W TDP
- Dual Sockel P, 2nd Gen Intel Xeon Scalable Prozessoren
- 24x DIMM Steckplätze, bis zu 6TB RAM DDR4-2933MHz ECC
- 2x hot-pluggable Nodes
- 6x 3.5 hot-swap Laufwerkseinschübe
- 2x PCI-E 3.0 x8, 1x PCI-E 3.0 x16 & 1x SIOM-Karte Unterstützung
- 2x 2200W redundante Stromversorgungen (Titanium Level)

- 2HE Rackmount Server, bis zu 165W TDP
- Dual Sockel P, 2nd Gen Intel Xeon Scalable Prozessoren
- 16x DIMM Steckplätze, bis zu 4TB RAM DDR4-2933MHz ECC
- 4x hot-pluggable Nodes
- 3x 3.5 hot-swap SATA Laufwerkseinschübe
- 2x PCI-E 3.0 x16 Steckplätze und 1x SIOM Kartenunterstützung
- 2x 2200W redundante Stromversorgung (Titanium Level)

- 8HE Rack SuperBlade Enclosure
- Bis zu 20 Blade Server
- Bis zu 2x 10GbE Switche
- 1 Management Modul
- 4x 2200W Netzteile (Titanium Level)

besonderes Highlight
2 Nodes in 1HE
- 1HE Rackmount-Server, bis zu 185W cTDP
- Dual Sockel P+, 3rd Gen Intel Xeon Scalable Prozessoren
- 16x DIMM-Steckplätze, bis zu 4TB RAM DDR4-3200MHz
- 2x hot-pluggable Nodes
- 4x 2.5 Zoll SATA/SAS hot-swap Laufwerkseinschübe
- 1x PCI-E 4.0 x16 LP Expansion-Slot
- 2x 1000W redundante Stromversorgungen (Titanium Level)

- 2HE 4-Node Rack Server, bis zu 165W TDP
- Dual Sockel P, 2nd Gen Intel Xeon Scalable Prozessoren
- 16x DIMM Steckplätze, bis zu 4TB RAM DDR4-2933MHz ECC
- 6x 2.5 Zoll hot-swap SATA3 Laufwerkseinschübe
- 2x PCI-E 3.0 x16 Steckplätze und 1x SIOM Kartenunterstützung
- Flexibel Netzwerkunterstützung über SIOM & dedicated IPMI 2.0
- 2x 2200W redundante Stromversorgungen (Titanium Level)

- 6HE Rackmount SuperBlade Enclosure
- Bis zu 14/28 Blade Servers
- Bis zu 2x Ethernet-Switch-Module
- 1x Management-Modul
- Bis zu 8x Kühlüfter
- Bis zu 8x 2200W hot-plug Stromversorgungen (Titanium Level)

besonderes Highlight
4 CPUs, bis zu 12TB RAM
- 2HE Rackmount Server, bis zu 250W TDP
- Quad Socket P+, 3rd Gen Intel Xeon Scalable Prozessoren
- 48x DIMM Steckplätze, bis zu 18TB RAM DDR4-3200MHz
- 24x 2.5 Hot-swap NVMe/SAS3/SATA3-Laufwerkeinschübe
- 6x PCI-E 3.0-Steckplätze
- 2x 10GbE RJ45 + 2x 10 GbE SFP+ mit Intel X710-TM4
- 2x 2000W redundante Stromversorgungen (Titanium Level)

- 2HE Rack 4 Node Server, bis zu 165W TDP
- Dual Socket P, 2nd Gen Intel Xeon Scalable Prozessoren
- 16x DIMM Steckplätze, bis zu 4TB RAM DDR4-2933MHz ECC
- 6x 2.5 Zoll hot-swap SAS/SATA Laufwerkseinschübe
- 2x PCI-E 3.0 x16 Steckplätze und 1x SIOM Kartenunterstützung
- 1x RJ45 IPMI LAN Anschluss, Netzwerkunterstützung über SIOM
- 2x 2200W redundante Stromversorgungen (Titanium Level)

- 2HE-Rack-Server, 250W TDP
- Dual Socket P + (LGA 4189), Intel Xeon Scalable Prozessoren
- Bis zu 4 TB: 16 x 256 GB DRAM, 6 TB: 8x 256 GB DRAM und 8x 512
- 6x 3.5 Hot-Swap-NVMe / SATA / SAS-Einschübe (6x 2.5 NVMe-Hybrid)
- Netzwerk-Konnektivität über AIOM (OCP 3.0-konform)
- S1: PCI-E 4,0 x 8 LP S2: PCI-E 4,0 x 8 LP S3: PCI-E 4,0 x 16 LP
- 2200W redundante Netzteile (Titanium Level)

- 2HE Rackmount Server, 4-way bis zu 250W TDP
- Quad Socket P+, 3rd Gen Intel Xeon Scalable Prozessoren
- 48x DIMM Steckplätze, bis zu 6TB RAM DDR4-3200MHz
- 8x PCI-E 3.0 x16-Expansion-Slots und 1x OCP 3.0
- 2x 10GbE LAN-Anschlüsse über Intel X710-AT2
- 2x 3200W redundante Stromversorgungen (Platinum Level)

- 2HE Rackmount Server, bis zu 165W TDP
- Dual Sockel P, 2nd Gen Intel Xeon Scalable Prozessoren
- 16x DIMM Steckplätze, bis zu 4TB RAM DDR4-2933MHz ECC
- 4x hot-pluggable Nodes
- 3x 3.5 hot-swap SAS/SATA Laufwerkseinschübe
- 2x PCI-E 3.0 x16 Steckplätze und 1x SIOM Kartenunterstützung
- 2x 2200W redundante Stromversorgungen (Titanium Level)

besonderes Highlight
4 hot-pluggable Nodes auf 2HE
- 2HE Rackmount Server, bis zu 165W TDP
- Dual Sockel P, 2nd Gen Intel Xeon Scalable Prozessoren
- 16x DIMM Steckplätze, bis zu 4TB RAM DDR4-2933MHz ECC
- 4 hot-pluggable Nodes
- 6x 2.5 Zoll hot-swap SAS/SATA Laufwerkseinschübe
- 2x PCI-E 3.0 x16-Steckplätze und 1 SIOM-Kartenunterstützung
- 2x 2200W redundante Stromversorgungen (Titanium Level)

- 4HE Rackmount Server, bis zu 165W TDP
- 4x Hot-pluggable Nodes
- Dual Sockel P, 2nd Gen Intel Xeon Scalable Prozessoren
- 12x DIMM Steckplätze, bis zu 3TB RAM DDR4-2933MHz ECC
- 8x 3.5 hot-swap SATA3 Laufwerkseinschübe
- 2x PCI-E 3.0 x16 Steckplätze
- 4x 1200W redundante Stromversorgungen (Titanium Level)
Brauchen Sie Hilfe?
Dann rufen Sie uns einfach an oder nutzen unser Anfrageformular.
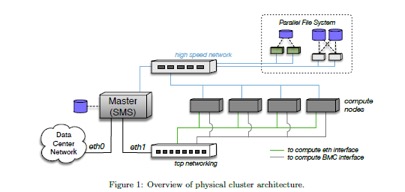
Aufbau eines HPC Clusters
- Der Cluster Server (Master oder Frontend genannt) verwaltet den Zugriff und stellt Programme und den Home-Datenbereich zur Verfügung.
- Die Cluster Nodes erledigen die Berechnung.
- Ein TCP-Netzwerk wird für den Informationsaustausch im HPC Clusters verwendet.
- Ein High Performance Network ist erforderlich, um die Datenübertragung mit sehr geringer Latenz zu ermöglichen.
- Der High Performance Storage (Parallel File System) ermöglicht den gleichzeitigen Schreib-Zugriff aller Cluster Nodes.
- Das BMC Interface (IPMI Interface) ist der Zugang für den Administrator zur Verwaltung der Hardware.
Alle Cluster Nodes eines HPC Clusters werden immer mit dem gleichen Prozessortyps des jeweiligen gewählten Herstellers ausgestattet. Verschiedene Hersteller und Typen werden in aller Regel nicht in einem HPC Cluster gemischt. Eine unterschiedliche Ausstattung mit Hauptspeicher und anderen Ressourcen ist durchaus möglich. Dies sollte dann aber in der Konfiguration der Job Control Software berücksichtigt werden.
Wann kommen HPC Cluster zum Einsatz?
HPC Cluster sind dann besonders wirkungsvoll, wenn sie für Berechnungen angewandt werden, die sich in verschiedene Teilaufgaben untergliedern lassen. Ebenso kann ein HPC Cluster aber auch eine Reihe kleinerer Aufgaben parallel zueinander bewältigen. Ein High Performance Computing Cluster ist zudem in der Lage, eine einzelne Anwendung für mehrere Nutzer gleichzeitig zur Verfügung zu stellen, um durch das simultane Arbeiten Kosten und Zeit zu sparen.
Je nach Ihrem Budget und Anforderungen kann HAPPYWARE Ihnen einen HPC Cluster zusammenstellen. Mit verschiedenen konfigurierten Cluster Knoten, einem High Speed Network und einem parallelen File System. Für das Management des HPC Clusters setzen wir auf die bekannte Lösung von OpenHPC, um die Verwaltung des Clusters effektiv und intuitiv zu gestalten.
Wenn Sie mehr über mögliche Anwendungsszenarien für HPC Cluster erfahren möchten, dann hilft Ihnen unser HPC-Ingenieur Herr Jürgen Kabelitz gerne weiter. Er leitet die Clusterabteilung und steht Ihnen unter der Rufnummer +49 4181 23577 79 für Fragen zur Verfügung!
HPC Cluster Lösungen von HAPPYWARE
Hier haben wir für Sie einige mögliche Konfigurationen von HPC Clustern zusammengestellt:
- Frontend oder Master Server 4 HE Cluster Server mit 24 3,5’’ Laufwerkschächten, SSD für das Betriebssystem, Dual Port 10 Gb/s Netzwerk Adapter, FDR Infiniband Adapter
- Cluster Knoten 12 Cluster Nodes mit dual CPU und 64 GB Arbeitsspeicher, 12 Cluster Nodes mit dual CPU und 256 GB Arbeitsspeicher, 6 GPU Computing Systeme mit je 4 Tesla V100 SXM2 und 512 GB Arbeitsspeicher NVIDIA Werte angeben, FDR Infiniband und 10 GB/s TCP Netzwerk
- High Performance Storage 1 Storage System mit 32 x NF1 SSD mit je 16 TB Kapazität, 2 Storage Systeme mit je 45 Hot-Swap Schächte, Netzwerkverbindung: 10 Gb/s TCP/IP und FDR Infiniband
- HPC Cluster Management – mit OpenHPC und xCAT Für das Management von HPC Clustern und Daten braucht es eine entsprechend leistungsfähige Software. Zu diesem Zweck bieten wir Ihnen mit OpenHPC und xCAT zwei bewährte Lösungen an.
- HPC Cluster mit OpenHPC OpenHPC ermöglicht grundlegendes HPC Cluster Management auf Linux- und OpenSource-Basis.
Leistungsumfang
- Forwarding der Systemlogs möglich
- Nagios Monitoring & Ganglia Monitoring – Opensource-Lösung für Infrastrukturen und skalierbares System Monitoring für HPC Cluster sowie Grids
- ClusterShell Event basierte Python Bibliothek für das parallele Ausführen von Befehlen auf dem Cluster
- Genders - statische Cluster Konfigurationsdatenbank
- ConMan - Serial Console Management
- NHC - Node health check
- Entwicklersoftware wie Easy_Build, hwloc, spack und valgrind
- Compiler wie GNU Compiler, LLVM Compiler
- MPI Stacks
- Job Kontrollsystem wie PBS Professionel oder Slurm
- Infiniband Support & Omni-Path Support für x86_64 Architekturen
- BeeGFS Support für das Mounten von BeeGFS Filesystemen
- Lustre Client Support für das Mounten von Lustre Filesystemen
- GEOPM Global Extensible Power Manager
- Unterstützung von INTEL Parallel Studio XE Software
- Unterstützung von lokaler Software mit der Modules Software
- Unterstützung von Nodes mit stateful oder stateless Konfiguration
Unterstützte Betriebssysteme
- CentOS7.5
- SUSE Linux Enterprise Server 12 SP3
Unterstützte Hardware Architekturen
- x86_64
- aarch64
HPC Cluster mit xCAT xCAT ist ein “Extreme Cloud Administration Toolkit” und ermöglicht ein umfassendes HPC Cluster Management.
Geeignet für folgende Anwendungen
- Clouds
- Cluster
- High-Performance -Cluster
- Grids
- Datacentre
- Renderfarms
- Online Gaming Infrastructure
- Oder jede andere System Zusammenstellung, die möglich ist.
Leistungsumfang
- Erkennen von Servern im Netz
- Ausführen von Remote System Management
- Bereitstellung von Betriebssystemen auf physikalischen oder virtuellen Servern
- Diskful (stateful) oder Diskless (stateless) Installation
- Installation und Konfiguration von Benutzersoftware
- Paralleles Systemmanagement
- Integration der Cloud
Unterstützte Betriebssysteme
- RHEL
- SLES
- Ubuntu
- Debian
- CentOS
- Fedora
- Scientific Linux
- Oracle Linux
- Windows
- Esxi
- und etliche andere
Unterstützte Hardware Architekturen
- IBM Power
- IBM Power LE
- x86_64
Unterstützte Virtualisierungs-Infrastruktur
- IBM PowerKVM
- IBM zVM
- ESXI
- XEN
Leistungswerte für mögliche Prozessoren
Als Leistungswerte wurde auf die Werte von SPEC.ORG zurückgegriffen. Dabei werden ausschließlich die Werte für SPECrate 2017 Integer und SPECrate 2017 Floating Point verglichen:
| Hersteller | Modell | Prozessor | Taktrate | # CPUs | # cores | # Threads | Base Integer | Peak Integer | Base Floatingpoint | Peak Floatingpoint |
|---|---|---|---|---|---|---|---|---|---|---|
| Giagbyte | R181-791 | AMD EPYC 7601 | 2,2 GHz | 2 | 64 | 128 | 281 | 309 | 265 | 275 |
| Supermicro | 6029U-TR4 | Xeon Silver 4110 | 2,1 GHz | 2 | 16 | 32 | 74,1 | 78,8 | 87,2 | 84,8 |
| Supermicro | 6029U-TR4 | Xeon Gold 5120 | 2.2 GHz | 2 | 28 | 56 | 146 | 137 | 143 | 140 |
| Supermicro | 6029U-TR4 | Xeon Gold 6140 | 2.3 GHz | 2 | 36 | 72 | 203 | 192 | 186 | 183 |
NVIDIA Tesla V100 SXM2 64Bit 7,8 TFlops; 32Bit 15,7 TFlops; 125 TFlops für Tensor Operationen.
HPC Cluster und mehr von HAPPYWARE – Ihr Partner für starke Cluster-Lösungen
Wir sind Ihr Spezialist für individuell konfigurierte und extrem performante Cluster – ganz gleich, ob es um GPU Cluster, HPC Cluster oder andere Setups geht. Gerne stellen wir auch für Ihr Unternehmen ein bedarfsgerechtes System zu einem fairen Preis zusammen.
Für wissenschaftliche Institutionen und Bildungsstätten bieten wir außerdem mit unserem Rabatt für Forschung und Lehre besonders günstige Konditionen. Sprechen Sie uns bei Interesse auf mögliche Rabatte an.
Möchten Sie mehr über die Ausstattung unserer HPC Cluster erfahren oder benötigen Sie eine individuell konzipierte Cluster-Lösung? Melden Sie sich unter der Nummer +49 4181 23577 79 bei unserem Cluster-Spezialisten Jürgen Kabelitz und lassen Sie sich passend zu Ihren Anforderungen beraten!